
为什么圭表化要把均值设为0、方差设为1?
先说均值。均值等于平均数,统统不雅测值加起来除以个数。
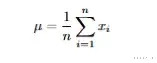
μ是均值,n是数据点总和,xᵢ是每个数据点,是以均值等于数据的要点位置。比如均值是20,那20等于均衡点。这不是说统统点到20的距离相等而是说双方的"分量"刚好在20这个位置对消掉。
{jz:field.toptypename/}而方差掂量的是数据有多差别,界说是每个值与均值偏差的平时的平均值。
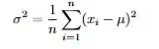
n是数据点总和,xᵢ是每个数据点,μ是均值。
那均值为0有什么用?
不错把数据念念象成坐标系里的一团“点云”。每个值减去均值(x — μ)之后,整团云就被平移到了原点位置。数据不再飘在某个边缘而是以原点为中心差别。
这对好多机器学习算法齐有自制,尤其是用梯度下跌的时辰。数据居中之后优化历程更均衡、管制也更快。因为特征如果一初始就偏离原点很远,磨练起来会贫寒不少。
那方差为1呢?
这是为了刺目某个特征"玷污"其他特征。
举个例子:年纪和薪资两个特征,年纪限度10-70,薪资限度10,000-70,000。告成喂给模子的话,模子会认为薪资频年纪贫苦1000倍(数字大嘛)。但这两个特征原来是镇定的,真钱投注app凭什么薪资就更贫苦?
是以圭表化等于除以圭表差,让统统特征的方差齐酿成1。这么年纪和薪资就在合并个量级上了,变化幅度差未几。年纪有个小波动,不会因为薪资数字大就被模子无视掉。

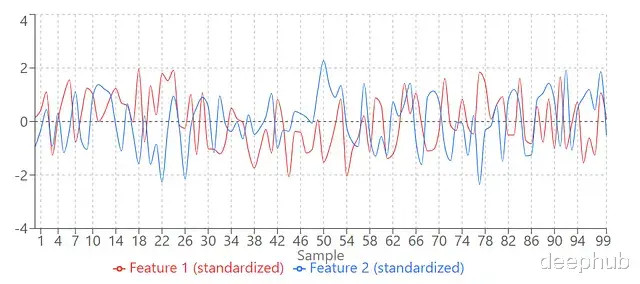
可视化戒指:
圭表化之前,特征1(红色,小圭臬)和特征2(蓝色,大圭臬)放一齐,红色那条险些看不见。圭表化之后,两个特征圭臬一致,齐能明晰败表示来。模子终于不错公道对待它们了。
什么时辰需要圭表化?逻辑转头、神经汇注、KNN这类用梯度下跌的算法,圭表化影响最大。
总结一下:
均值为0让数据居中,方差为1让特征圭臬搭伙。两者合作,算法学得更快,也不会偏心某个特征。至于什么时辰该用圭表化、什么时辰该用MinMaxScaler,浑厚说我也还在摸索。
作家:vaishnavi

2026年,线崇高量越来越贵,获客资本居高不下,越来越多品牌开动把眼神再行投向“...

在2026年2月8日,华中师范大学国家文化产业研究中心原副主任、教授、博士生导师...

春节周边,互联网巨头在AI战场再次兵戎再会。 腾讯元宝秘书2月1日上线春节步履,...

IT之家 3 月 10 日音信,vivo 家具司理韩伯啸当天公布了两款手机增距镜...



 备案号:
备案号:  QQ:
QQ:

 返回顶部
返回顶部